Overview of Data Storage Options for OpenLMIS Reporting Platform
This document provides an overview of data storage technology options for the OpenLMIS data warehouse. The document systematically identifies each available technology, Hadoop (HDFS), Druid and Relational Database Management Systems (RDBMS). Each of these data storage solutions have benefits that should be evaluated by the community. Note that this is an evaluation of a subset of technologies previously deemed relevant to the reporting effort. It is not meant to be an exhaustive comparison and we therefore do not evaluate NoSQL, Graph, time series, or other alternative databases.
OpenLMIS Data Warehouse Strategy and the Role of Data Storage
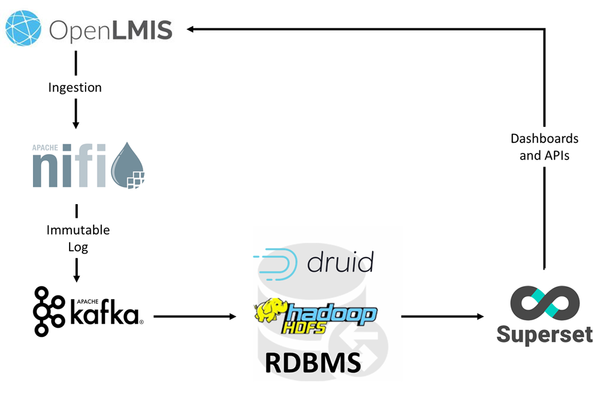
The OpenLMIS data warehouse strategy includes multiple processes for data ingestion, stream processing, storage and visualization. This data storage options overview is only one component of the data warehouse strategy and should be considered as a decision that can change over time.
Information is ingested from the OpenLMIS v3 microservice APIs using Apache NiFi. Each endpoint is queried on a regular schedule and pushed to Apache Kafka. Kafka creates an immutable log of each transaction. These logs are incredibly important for OpenLMIS because they will not change and can be replayed at any point in time. For example, we may wish to change the structure of a particular table in the data warehouse. In order to do this, we need to build the appropriate Kafka routing topics and destination structure in the data storage system. Then, we replay the Kafka log from a particular point in time and all information will be processed.
Once processed through Kafka, the data hits the data storage system where it is indexed and made available to the SuperSet visualization engine. In this case, the data storage system can be considered a view on top of the underlying data ingestion logs that are stored in Kafka and we can choose one or multiple data storage technologies and structures to truly meet the reporting needs. In this case, the trade off is around current scale vs future scale and the responsiveness of the visualization engine. If a particular implementation needs to scale to another storage technology, they can do so and rerun the logs from the beginning of time, fully replicating the entire history in the new data storage technology.
Introduction to Each Technology
HDFS
https://searchdatamanagement.techtarget.com/definition/Hadoop-Distributed-File-System-HDFS
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. It employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable clusters.
HDFS supports the rapid transfer of data between compute notes. When HDFS takes in data, it breaks the information down into separate blocks and distributes them to different nodes in the cluster, thus enabling highly efficient parallel processing.
HDFS is specially designed to be highly fault-tolerant. HDFS can be configured to replicate each piece of data multiple times and distribute the copies to individual nodes, placing at least one copy on a different server rack than the others. As a result, the data on nodes that crash can be found elsewhere within the cluster.
There are a number of popular querying tools for HDFS, including Apache Hive, Apache Impala, and Apache Drill, all of which use SQL. Apache Pig and Apache Mahout are data analysis and machine learning platforms, respectively, that are commonly run over HDFS.
Druid
Druid is an open-source data store designed for sub-second queries on real-time and historical data. It is primarily used for business intelligence (OLAP) queries on event data. Druid provides low latency (real-time) data ingestion, flexible data exploration, and fast data aggregation. Existing Druid deployments have scaled to trillions of events and petabytes of data for clients like Alibaba, Airbnb, eBay, Netflix, and Yahoo.
Organizations have deployed Druid to analyze user, server, and marketplace events across a variety of industries including media, telecommunications, security, banking, healthcare, and retail. Druid is a good for if you have the following requirements:
- You require fast aggregations and OLAP queries
- You want to do real-time analysis
- You have or are expecting a high volume of data
- You need a data store that is always available with no single point of failure
Druid stores data in JSON format and uses JSON to construct its queries. It has a SQL plugin that we have not yet explored in depth.
Druid is partially inspired by existing analytic data stores such as Google’s BigQuery/Dremel, Google’s PowerDrill, and search infrastructure. Druid indexes all ingested data in a custom column format optimized for aggregations and filters. A Druid cluster is composed of various types of processes (called nodes), each designed to do a small set of things very well.
RDBMS (PostgreSQL)
A relational database management system (RDBMS) is a collective set of multiple data sets organized by tables, records, and columns. OpenLMIS uses PostgreSQL for the core data storage system. RDBs establish well-defined relationships between database tables that communicate and share information, facilitating data searchability, organization, and sharing.
RDBs typically use Structured Query Language (SQL), a widely known query language that provides an easy programming interface for database interaction.
RDBs organize data in different ways. Each table is known as a relation, which contains one or more category columns. Each table record (or row) contains a unique data instance defined for a corresponding column category. One or more data or record characteristics relate to one or many records to form functional dependencies.
RDBs performs “select,” “project,” and “join” database operations, where select is used for data retrieval, project identifies data attributes, and join combines data relations.
RDBs have many other advantages, including:
- Easy extensibility, as new data may be added without modifying existing records. This is also known as scalability
- New technology performance, power, and flexibility from multiple data requirement capabilities
- Data security, which is critical when data sharing is based on privacy. For example, management may share certain data privileges and access and block employees from other data, such as confidential salary or benefit information.
Metrics for evaluation
- Query speed
- Ease-of-querying
- Scalability
- Security
- Uptime
- Assessment of learning curve for existing OpenLMIS implementers
Pros and Cons
Pros | Cons | |
HDFS |
|
|
Druid |
|
|
RDBMS |
|
|
What are the performance differences at different scales?
We wish to ultimately maintain a positive user experience for users who view the Superset dashboard. This user experience includes ensuring that the information displayed is updated at an acceptable interval, returns data within an acceptable amount of time and maintains the expected business logic that’s defined in the OpenLMIS. The underlying database technology and structure have an impact on all three.
Each time a user views a Superset dashboard, each chart performs a query against the database. Some dashboards have 30 charts, resulting in 30 simultaneous queries, each of which are managed by the underlying hardware. Druid is built to be performant at these tasks out of the box. RDBMS will require structured tables and stored processes to ensure each query is performant.
We are not ready to do a performance assessment at this time. This assessment needs to be done independently based on the scale that’s assigned by the OpenLMIS community and we need to generate demo data at that scale in order to properly assess the performance differences at different scale.
What are the differences in hardware that's needed to support each?
This assessment is dependent on a standard scale. As a replacement, we have identified best practices in each community for piloting each system and scaling each. Each technology is able to be scaled to any size as long as the system architects determine the correct approach. For example, HDFS and Druid are built on clusters, where they run on top of commodity hardware and maintain the storage, indexing, etc. across multiple machines. RDBMS are a bit different, where we would prefer to scale vertically before splitting the database across multiple machines, although horizontal scalability is available for many RDBMS.
HDFS
HDFS utilizes a Zookeeper control machine to manage the data storage. Below is a list of specifications for a pilot machine:
For pilot deployments, you can start with 1U/machine and use the following recommendations:
Two quad core CPUs | 12 GB to 24 GB memory | Four to six disk drives of 2 terabyte (TB) capacity.
The minimum requirement for network is 1GigE all-to-all and can be easily achieved by connecting all of your nodes to a Gigabyte Ethernet switch. In order to use the spare socket for adding more CPUs in future, you can also consider using either a six or an eight core CPU.
For small to medium HBase clusters, provide each ZooKeeper server with around 1GB of RAM and, if possible, its own disk.
As you can see, Hadoop works best in a clustered environment. Below is a list of hardware requirements for production quality installations:
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.4/bk_cluster-planning/content/conclusion.html
Machine Type | Workload Pattern/ Cluster Type | Storage[1] | Processor (# of Cores) | Memory (GB) | Network |
Slaves | Balanced workload | Twelve 2-3 TB disks | 8 | 128-256 | 1 GB onboard, 2x10 GBE mezzanine/external |
Compute-intensive workload | Twelve 1-2 TB disks | 10 | 128-256 | 1 GB onboard, 2x10 GBE mezzanine/external | |
Storage-heavy workload | Twelve 4+ TB disks | 8 | 128-256 | 1 GB onboard, 2x10 GBE mezzanine/external | |
NameNode | Balanced workload | Four or more 2-3 TB RAID 10 with spares | 8 | 128-256 | 1 GB onboard, 2x10 GBE mezzanine/external |
ResourceManager | Balanced workload | Four or more 2-3 TB RAID 10 with spares | 8 | 128-256 | 1 GB onboard, 2x10 GBE mezzanine/external |
Druid
Source: http://druid.io/docs/latest/configuration/production-cluster.html
Just like HDFS, Druid requires a number of nodes to run on a cluster. The linked source document defines a typical druid cluster, which contains Overlord, Coordinator and Zookeeper on a single node and nodes that respond to queries on separate machines, Historical, Broker and MiddleManager. The current reporting stack is being run on an AWS M5.4xlarge EC2 instance which contains 16 cores and 64GB of RAM attached to a 100GB EBS..
RDBMS
The relational database requires a much simpler hardware setup than HDFS and Druid because there’s no need to run management systems. The RDBMS should be run on a single machine that has specifications similar to the OpenLMIS implementation. Generally speaking, we would recommend a system with 12 cores and 24-32 GB of RAM to run the ETL processes and perform queries based on a flattened data model.
Assuming that we will ingest everything from OpenLMIS, will we need relationships? What is the impact on not having relationships in Superset?
The OpenLMIS architecture contains inherent business logic that needs to be replicated in the reporting system. The information is currently stored in microservices and will be extracted from NiFi. At this time, we do not know if ingesting all information into a single druid table is a viable approach to modeling the data in a performant way. We do recognize that there are inherent relationships between differing information in microservices, but need more information on the different database structures and reporting metrics when assessing the impact of having or not having the ability to create database relationships between multiple data sources from multiple microservices.
Is there a way to start small and gradually progress from PostgreSQL to a key/value datastore like Druid?
Yes, it would require us to reindex all of the historical data in PostgreSQL into Druid. This does not need to come from PostgreSQL, but could come from the source system if it’s still available.
Additionally, and more importantly, it would likely require us to rebuild and revalidate the indicator definitions and visualizations in Superset. Depending upon the level of complexity of the indicator definitions, this could be a very resource-intensive process. The current DISC indicators are fairly complex, and this is not a trivial effort.
We would need to evaluate the particular use case to determine whether it’s more efficient to invest the resources up front into building out the stack in Druid versus rebuilding at a later date.
OpenLMIS: the global initiative for powerful LMIS software