Translations
- Rich Magnuson (Deactivated)
- Mary Jo Kochendorfer (Deactivated)
- Nikodem Graczewski (Unlicensed)
Introduction
OpenLMIS uses standard property files for localized strings. Transifex is a company and online translation-collaboration service used by translators to modify and manage translations. OpenLMIS’ main Transifex page is at https://www.transifex.com/openlmis/.
Cost and Benefit of Using Transifex
Transifex bridges the gap between translators and technologists. It’s ill advised to simply give third-party translators write-access to OpenLMIS’ codebase and expect them to modify translation files directly within git. It’s also difficult to share common translations amongst multiple projects this way. One possible approach is to involve a developer in the translation process. Shuffling translations files around via email, though, introduces the likelihood that they will be saved or opened with the wrong encoding. This approach also shifts translation work onto a developer needlessly, and does nothing to promote the reuse of translations. Transifex addresses these issues.
Transifex is free to use for open-source projects. Although they generally reserve advanced functionality for paying customers, Transifex has generously made an exception specifically for VillageReach. We are allowed up to 30 contributors under this license so the number of contributors must me managed. The OpenLMIS Community Manager, Tenly Snow (Deactivated), will manage the translations so please connect with her if you would like to be a contributor to this project. We leverage Translation Memory which will save us significant time and cost at the inception of new projects.
Transifex Project Structure
OpenLMIS version 3 is a microservice architecture so there multiple transifex "projects" associated with each service, both one project for the front and back-end. Due to the multiple projects, there isn't "one" umbrella project for implementers to use as the primary store for all translations. To allow for the flexible customization of deployments, each deployment will have its own set of dedicated projects. It is expected that most translations within these deployment-specific projects will originate from the following list of 3.x projects and can be added to the deployment-specific projects via a file upload.
OpenLMIS 3.x projects are listed below. Only use these for version 3.
We are only supporting (fr) for French and (pt) for Portuguese.
- OpenLMIS Auth UI
- OpenLMIS CCE UI
- OpenLMIS Fulfillment UI
- OpenLMIS ReferenceData UI
- OpenLMIS Report UI
- OpenLMIS Requisition UI
- OpenLMIS Stock Management UI
- OpenLMIS UI Components
- OpenLMIS Layout
- Openlmis-auth
- Openlmis-fulfillment
- Openlmis-notification
- Openlmis-referencedata
- Openlmis-requisition
- Openlmis-stockmanagement
The following transifex projects are NOT related to the 3.x version and are discouraged from being used in any new deployments of OpenLMIS.
OpenLMIS 2.0 - Contains translations for every language into which OpenLMIS 1 and 2.x has been localized. This project may be thought of as the 'master' project from which other projects (used for individual country deployments) draw the majority of their translations. Because our demo systems are not country-specific and therefore lack a need for particular customization, they typically retrieve their translations directly from this project.
OpenLMIS Global - A project that only contains French translations. As of 10/2016, it hasn't been updated for nearly a year and a half and has thus been archived.
OpenLMIS Mozambique- Used by the CHAI team for their ESMS project.
OpenLMIS-SELV - Contains all translations for Mozambique’s OpenLMIS implementation.
OpenLMIS-SIIL - Contains all translations for Benin’s OpenLMIS implementation. Note that historical translation files created prior to the adoption of Transifex reside in /Dropbox (VillageReach)/OpenLMIS Projects/SELV/Archived_SELV_Translation_Files.
testProject - A project currently configure for use with Transifex Live (discussed in the Context for Translators section below).
Historical Translation Files - SELV - Translation files used for SELV before the adoption of Transifex may be found at /Dropbox (VillageReach)/OpenLMIS Projects/SELV/Archived_SELV_Translation_Files.
Translation Reuse
By design, OpenLMIS’ various implementations share a lot in common. This includes webpages and the text that appears within them. Allowing translations to be shared amongst projects is thus important – and fundamentally congruent with OpenLMIS’ vision of shared benefit.
Transifex doesn’t offer a way of directly linking projects such that children inherit from parents and translations defined within the former don’t have to be duplicated within the later. It does, however, offer something called Translation Memory. This is a feature normally reserved for customers paying thousands of dollars a year. Because Transifex supports VillageReach’s mission, however, they’ve generously agreed to freely activate it for us. Transifex has already been hosting OpenLMIS’ projects free of charge for years. They deserve extreme gratitude for allowing us use of this advanced feature as well.
Translation Memory isn’t something we previously had access to. It’s anticipated that, at the inception of new projects, it will allow us to reuse the translations defined in existing ones.
Translation Reuse II – Lessons Learned
With neither the benefit of linked projects nor Translation Memory, our previous guidance to translators was to use tools like Beyond Compare and Text Mechanic to manually manage the reuse of translations among projects. Transifex allows translation key-value pairs to be easily uploaded and downloaded to/from projects. The idea for reusing translations in a source project within a preexisting destination project was thus to:
1. Download existing translations from the two projects.
2. Use Text Mechanic to alphabetically sort the two files, thereby making their content match line-by-line as closely as possible.
3. Use Beyond Compare to compare the resultant files, selectively overriding lines within the destination file with entries in the source file.
4. Upload the modified destination file into the destination project.
A variety of complications made this approach overly cumbersome for translators. The biggest problem is that, surprisingly, the data downloaded from a Transifex project doesn’t exactly mirror that content originally uploaded. Downloads are delivered as ISO-8859 files containing escaped characters as defined in the Java .properties file specification. These escape characters are treated as non-escaped content, however, when encountered within a file uploaded to Transifex. This incongruence means that downloading a file from Transifex and immediately uploading the exact same file back into Transifex will introduce erroneous escape character into your translations. The problem compounds every time you perform such an operation.
Other problems with manually managing files include:
* When uploading a file, it's easy to use the wrong encoding and thus to get garbled results within Transifex. Even worse is the fact that it’s easy to overlook the problem. This seems to have happened to SELV's Portuguese and to have gone unnoticed for a long time within our production system.
* Translations may optionally span multiple lines. In such cases, they’ll erroneously be broken apart when sorting the properties file.
* Translation files aren’t always consistent in terms of whitespace. Most entries are of the form "myKey = myValue," though some appear within files as "myKey=myValue" (sans whitespace). Such discrepancies degrade the usefulness of alphabetically sorting files, and inversely increase the difficulty of comparing them.
For these reasons, the manual approach to translation-management is likely to involve lots of developer time. As a developer responsible for helping a translation effort, I found it necessary to write scripts to sort files, strip whitespace, remove escape-characters, and merge translation files with one another. Even with the scripts, it was easy to make mistakes and difficult to catch them.
Our shift toward the use of Translation Memory is intended to return the art of translation exclusively back to translators.
Workflow for Developers
See the Style Guide for instructions for using message keys and transifex.
A Note For Translators
Translations made within Transifex do automatically propagate to OpenLMIS as it is part of the build process. If translators use certain chacters or use the "enter" button, it will break the build. Please be mindful of how you conduct translations to decrease the risk of breaking things downstream. At this time we do not have a automated way to fix issues when input directly into Transifex.
IMPORTANT: Do not press enter on multi-line strings as it creates an error in our JSON.
You can either copy the whole source text OR click on the special character in the source text (as see below).
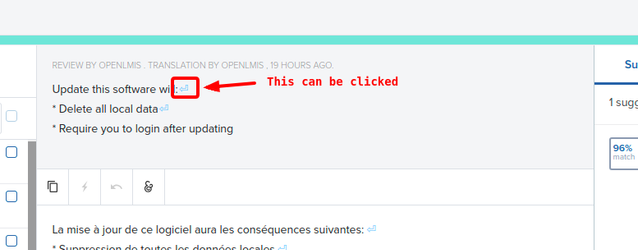
Thank you.
Providing Context for Translators
Translation keys occasionally appear in separate parts of OpenLMIS, and within different contexts. (Vidya specifically mentioned this regarding the push and pullsides to OpenLMIS.) To address this, Transifex offers a really nice feature called Live which:
A) Allows translators to browse to a live website, click a phrase (in English, for example) within it, and type a translation for the phrase.
B) Optionally incorporates these translations into the live version of a website in real-time.
I experimented with Transifex Live, and think it's a great offering. Unfortunately, though, it doesn’t currently seem to suit us. This is because:
A) It creates JSON, whereas OpenLMIS has historically used property files. It wouldn't likely be trivial to make this change in a way that would work for OpenLMIS' offline-mode. Transifex Live is designed for use with online websites.
B) Transifex Liveassumes a human-facing interface. Much of OpenLMIS 3.x, however, is being built without a direct interface. These components ("services") still require translation, though, and would thus require use of Transifex's traditional means of translation.
In light of this, we discussed deploying versions of OpenLMIS which display translation-keys rather than actual translations. This would help non-technical translators glean context. Until we get to this point, however, technically inclined translator's may use Google Chrome's Developer Tools. Right-clicking any element within a page yields a menu with an Inspect option. Choosing it opens the Developer Tools and displays the HTML that defines the field under inspection. Translated elements within OpenLMIS will have an "openlmis-message" attribute set to the translation-key intended for use within Transifex. The Developer Tools can be set to show the value of any element the user hovers over, thereby allowing translators to easily determine the keys associated with UI elements of interest.
Related content
OpenLMIS: the global initiative for powerful LMIS software